Appearance
Stream Data From Apache Kafka to Yellowbrick
Description
This tutorial explains how to set up an integration between Apache Kafka and Yellowbrick. This integration enables streaming from a Kafka topic directly into a Yellowbrick table.
Learning Objectives
By completing this tutorial, you will understand how to do the following:
- Configure Kafka Connect for Yellowbrick.
- Simulate a real-time data stream.
- Route messages from a Kafka topic directly into a Yellowbrick table.
Solution Overview
Apache Kafka is an open source, distributed event streaming platform used to create high-performance data pipelines, perform streaming analytics, and integrate data for mission-critical applications.
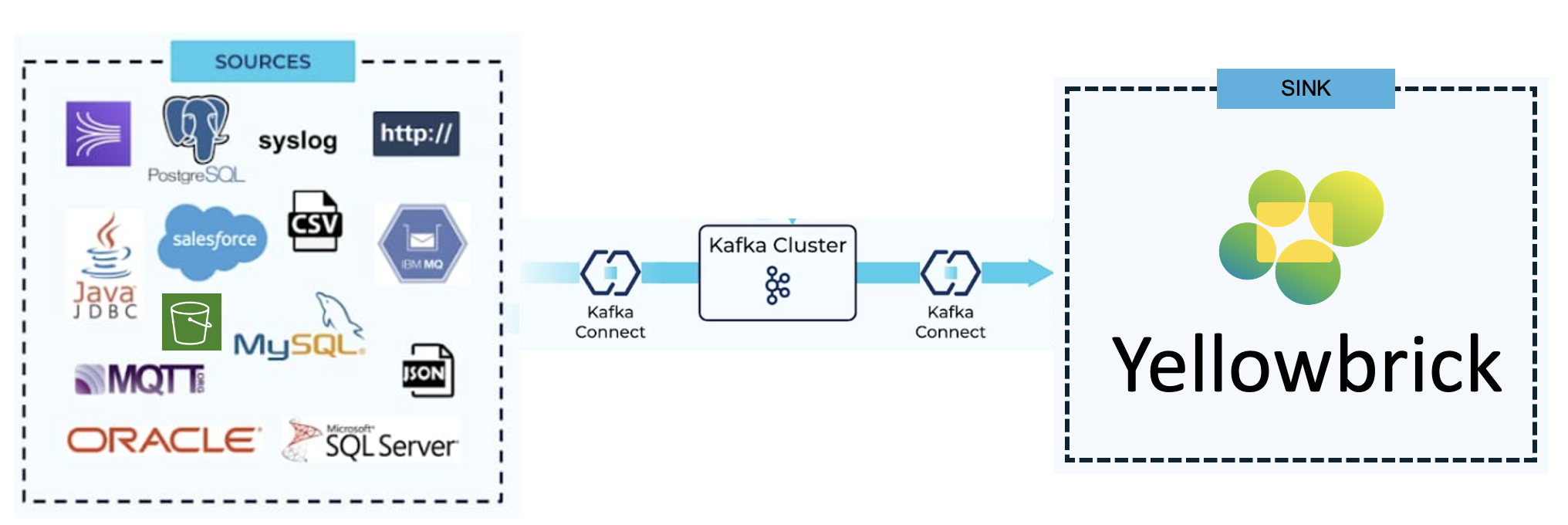
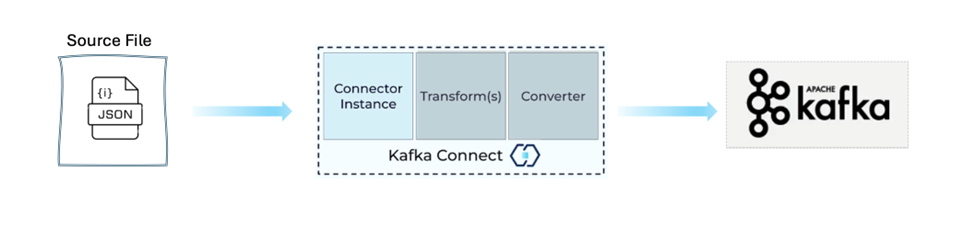
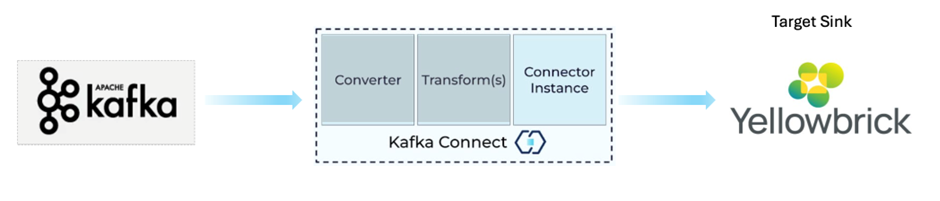
Kafka Connect includes two types of the following connectors:
- Source Connector: Imports data from source databases and streams CDC (Change Data Capture) updates, time-series data, and other real-time updates to Kafka topics. It can also collect metrics from application servers for low-latency stream processing.
- Sink Connector: Delivers data from Kafka topics into target platforms, such as Yellowbrick for downstream analytics and OLAP workloads.
Prerequisites
To complete this tutorial, ensure you have the following prerequisites:
- Apache Kafka is not available on your machine.
Note: If you already have Kafka or are using a managed platform such as Confluent Cloud, please directly visit Set Up Kafka Connect to Stream Source Data to Kafka.
- A Linux environment is present.
Note: If you are using Windows without the WSL (Windows Subsystem for Linux), replace the
.shcommands with their PowerShell or.batequivalents.
- Access to a Yellowbrick environment.
Step-By-Step Guide
Set Up Kafka
- Download Apache Kafka
Download the latest Kafka binaries from the Apache Kafka Downloads Page.
Note: Please refer the installation directory as
$KAFKA_HOMEthroughout this tutorial.
Start Services
a. Open terminal windows, navigate to$KAFKA_HOME, and run the following commands:bashbin/zookeeper-server-start.sh config/zookeeper.properties bin/kafka-server-start.sh config/server.propertiesb. Verify that both Zookeeper and Kafka services start without error messages.
Test the Kafka Service
Use the following bash commands in the terminal to test the Kafka service:
bash# Create a new test topic bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test # List topics to verify creation bin/kafka-topics.sh --list --bootstrap-server localhost:9092 # Produce messages to the Kafka topic bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test Hello, World It Is a Bright New Day Time to Innovate and Make a Change # Consume messages from the Kafka topic bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningExpected Output:
The expected output is as follows:
Hello, World
It Is a Bright New Day
Time to Innovate and Make a ChangeOnce verified, you might close these terminals.
Set Up Kafka Connect to Stream Source Data to Kafka
Perform the following commands in the terminal:
Configure the Source Connector
Editconnect-file-source.propertiesin$KAFKA_HOME/config:bashname=local-file-source connector.class=FileStreamSource tasks.max=1 file=test.txt topic=connect-testDownload and Set Up Configuration Files
Download the required files from the Yellowbrick GitHub Repository and extract them into$KAFKA_HOME/configYB.Verify the Plugin Path
Inconnect-standalone.properties, ensure theplugin.pathpoints to the correct JAR file:bashplugin.path=libs/connect-file-3.7.0.jarPrepare the Source Data
Downloadyour-file.txtand place it in$KAFKA_HOME:bashcat your-file.txt >> ybd-source-json.txtStart Kafka Connect
bashbin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.propertiesVerify Message Reception
bashbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-source --from-beginning
Configure Kafka Connect for Yellowbrick
Perform the following commands in the terminal:
Install YB Tools
Download and install YBTools.
Copy the Kafka connector JAR to$KAFKA_HOME/libs:bashcp /ybtools/integration/kafka/kafka-connect-yellowbrick-6.9.0-SNAPSHOT-shaded.jar $KAFKA_HOME/libsCreate a Target Table in Yellowbrick
In the Yellowbrick SQL Editor, run:sqlCREATE SCHEMA kafka; CREATE TABLE kafka.kafka_ybd_source_load ( col1 VARCHAR(30), col2 VARCHAR(30), tstmp TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) DISTRIBUTE RANDOM;Configure the Sink Connector
Editconnect-YB-sink_t2.propertieswith your Yellowbrick connection details:yamlyb.hostname=myinstance.aws.yellowbrickcloud.com yb.port=5432 yb.database=odl_user_XXXXXX_db yb.username=odl_user_XXXXXX yb.password=<your password> yb.table=kafka_ybd_source_load yb.schema=kafka yb.columns=col1,col2Update Kafka Connect Port
To avoid port conflicts, editconnect-standalone.properties:bashlisteners=http://0.0.0.0:8085Start the Sink Connector
bashbin/connect-standalone.sh configYB/connect-standalone_t2.properties configYB/connect-YB-sink_t2.propertiesVerify Data Ingestion
In the Yellowbrick SQL Editor, run:sqlSELECT * FROM kafka.kafka_ybd_source_load;Test Continuous Streaming
Add more data to the source file:bashcat your-file.txt >> ybd-source-json.txtQuery the Yellowbrick table to confirm new data gets inserted.
Clean Up
End Kafka Connect processes for both source and sink pipelines.
Stop Kafka and Zookeeper services.
Remove temporary files using the following bash command:
bashrm /tmp/connect.offsets rm -r /tmp/kafka-logs rm -r /tmp/zookeeper
✅ You have successfully demonstrated data streaming from Kafka into a Yellowbrick table.