Appearance
Virtual Compute Clusters
Your Yellowbrick VPC deployment is a dedicated and provisioned data warehouse in which you can create your own instances and clusters, which define the availability of hardware resources in the cloud.
A single deployment can have multiple instances, and an instance can have multiple clusters. An instance is a container for all the resources that may be shared among all of its clusters. A cluster is a set of assigned resources (worker nodes) that can execute database operations: load tables, run queries, and so on.
When you create a cluster, its hardware limits are constrained by the maximum resources available in the instance where you create it. Note the availability comments under Limit in the following example. You must choose one instance type per cluster; you cannot have a mixed set of worker nodes for any given cluster. The node count is limited to a maximum of 64 per cluster.
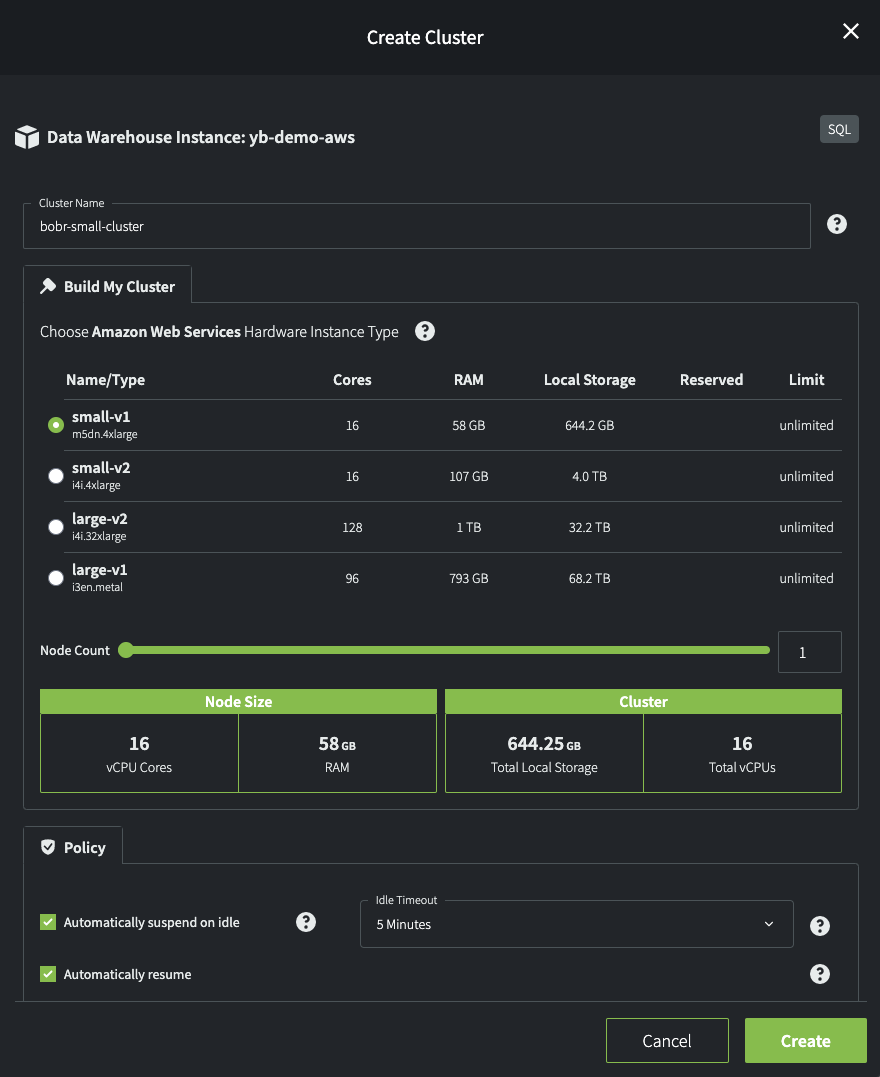
When you click Create, the cluster is provisioned for you in four stages: Preparing, Configuring, Starting, and Running. Each state shows the number of worker nodes that have reached that state. The cluster itself remains in Creating state until the four stages are complete.
Cluster Policy Options
Every cluster has an operating policy, as defined by the following options:
- Default cluster
- Every instance must have a default cluster that completes work when other clusters are suspended or unavailable. (This option is not visible if a default cluster has already been created for an instance.)
- Automatically suspend on idle
- This option ensures that a cluster does not consume resources when it is not being used.
- Automatically resume
- This option starts up a cluster automatically when its use is requested. The cluster will resume on submission of the first query that attempts to use it.
- Initially suspended
- This option suspends a cluster on creation, for situations where it is not intended for immediate use, but only when explicitly started (resumed).
- Workload Management Profile
- Each cluster can be assigned a specific WLM profile, or it can run with the
defaultprofile.
Default and System Clusters
A Yellowbrick instance must have one and only one default cluster, which remains running as the default resource for executing queries and other operations. If an instance has only a single cluster, it is by definition the default cluster. If an instance has only a single cluster, it is also implied to be the system cluster. The system cluster is a cluster designated to do all system work (background operations that run under internal system accounts). The default cluster and system cluster may be the same, or they may be set separately with ALTER SYSTEM SET CLUSTER commands.
A user may have a designated default cluster where all queries submitted by that user are run. The default cluster for a user may be set with an ALTER USER SET DEFAULT_CLUSTER command.
Operations That Do Not Require a Running Cluster
A running cluster is not needed for all queries and system operations. Users can run "front-end" queries, and the system can run commands that manage the instance. An instance is operational in this way before its first (default) cluster is created, and that cluster can be managed (suspended/resumed).
CREATE DATABASE, commands that create external objects, and other high-level commands do not require a running cluster; they are run by the front-end PostgreSQL database. You can run COUNT(*) queries, and return the results of certain system functions, such as CURRENT_DATABASE() and CURRENT_USER, when no FROM clause is present in the query. You can also query certain system views, but not the sys.log_query set of views.
Note: If you are creating your own primary storage for the databases in a given data warehouse instance, you should create that storage before creating any clusters or databases. See CREATE EXTERNAL LOCATION.
Modifying Clusters
After creating a cluster, you can modify it in a few ways:
SUSPEND/RESUMEthe cluster and apply a specified wait time.- Set the automatic
SUSPEND/RESUMEpolicy. RENAMEthe cluster.- Scale the cluster up or down by adding or subtracting from the node count.
- Associate the cluster with a different WLM profile.
See also ALTER CLUSTER.
Parent topic:Provisioning the Data Warehouse