Appearance
Queries and Administrative Tasks
Yellowbrick Manager includes a Query Editor where you can write, import, and run queries and scripts. You can run any Yellowbrick-supported SQL command in this tool, given that the right permissions have been granted to the current user. Look for the following icon on the left side of the home page:

Important: The top part of the editor provides controls for making or changing a database connection. Before running queries and other commands, make sure you are connected to the correct instance, cluster, and database, that the search path for schemas is set appropriately, and that you are running as the intended user (or role).
If any of the following selections are not correct, the query or command that you attempt to run may return errors:

Each query tab you open (with the + icon) can have a different set of connection properties. Given the appropriate connection details and user privileges, you can run simple or complex queries; create, drop, and alter objects; insert, update, and delete data; and run various administration commands.
The editor provides auto-completion assistance for standard SQL, making it quick and easy to run commands that use Yellowbrick-specific syntax and functions.
You can use the menu bar below the query-editing area to see results, messages, query plans, and query statistics.
The Explore tab provides several different ways to visualize query results.
The Query History tab (click History in the top-right of the editor) stores your SQL activity so you can easily see what has been run, search for specific commands, and re-run commands and scripts.
Generated SQL for UI Features
Yellowbrick Manager generates SQL when you carry out essential database operations via the user interface. Because of this seamless integration, users with little coding experience can run perfectly formed SQL in the Query Editor by copying and pasting (and, if necessary, editing) the generated syntax.
The following example shows an external storage object created for S3 data loading. The SQL button highlighted at A only needs to be selected to generate the SQL shown at B. The code is copied to the clipboard using the Copy to Clipboard button shown at C. The code can be pasted into the Query Editor and edited or run as is.
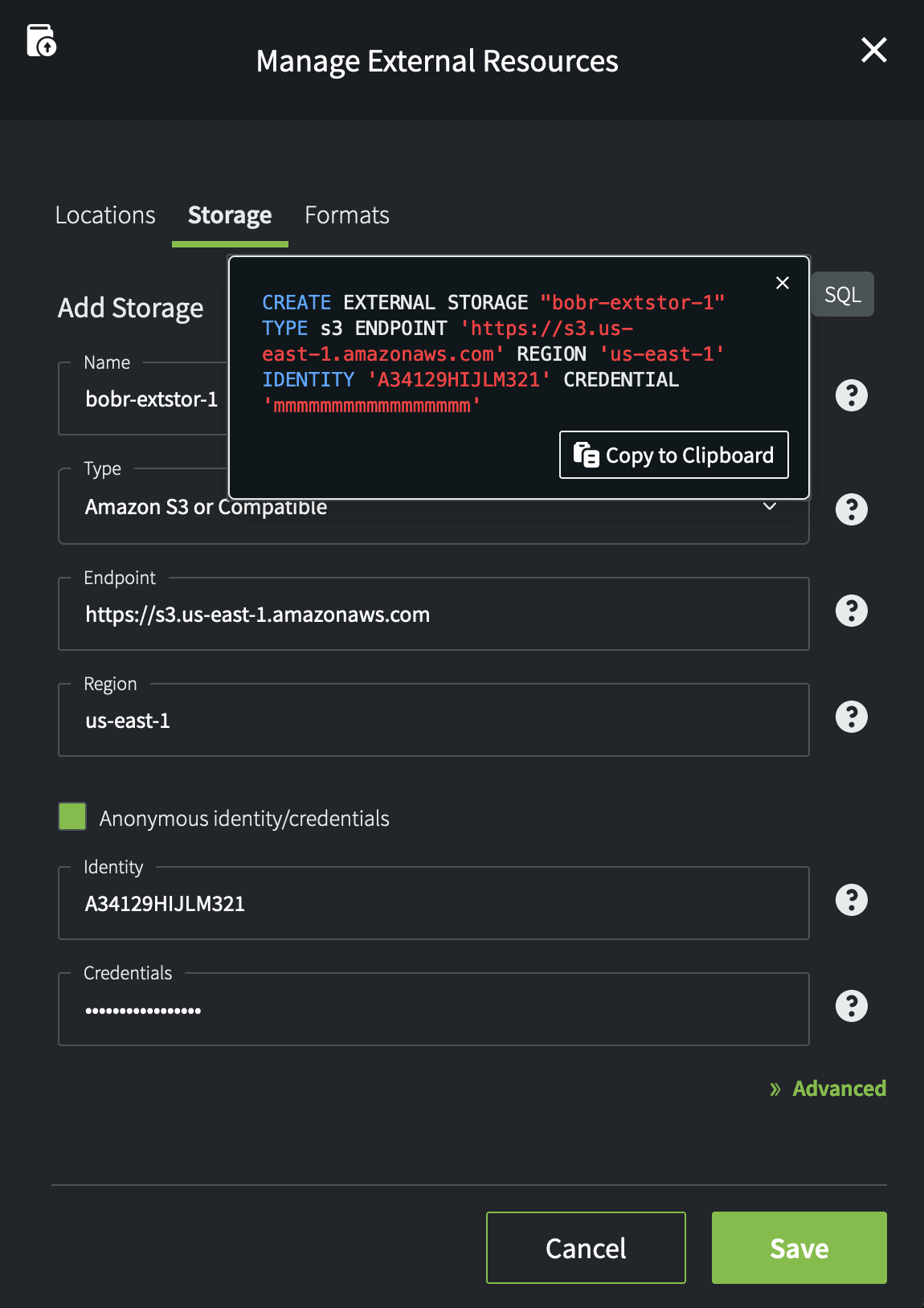
This SQL integration feature is available for several UI tasks, including:
- Creating and managing clusters
- Creating external storage, location, and format objects
- Loading data from object storage
- Resubmitting queries from the Query History and Activity logs
Query Activity
The Activity tab for a running instance gives you access to regular queries, session information, and other database operations:
You can use this feature to isolate and track activity for bulk loads, for example. In this case, three loads have been run on the same table for a given instance, one of which failed with an error:
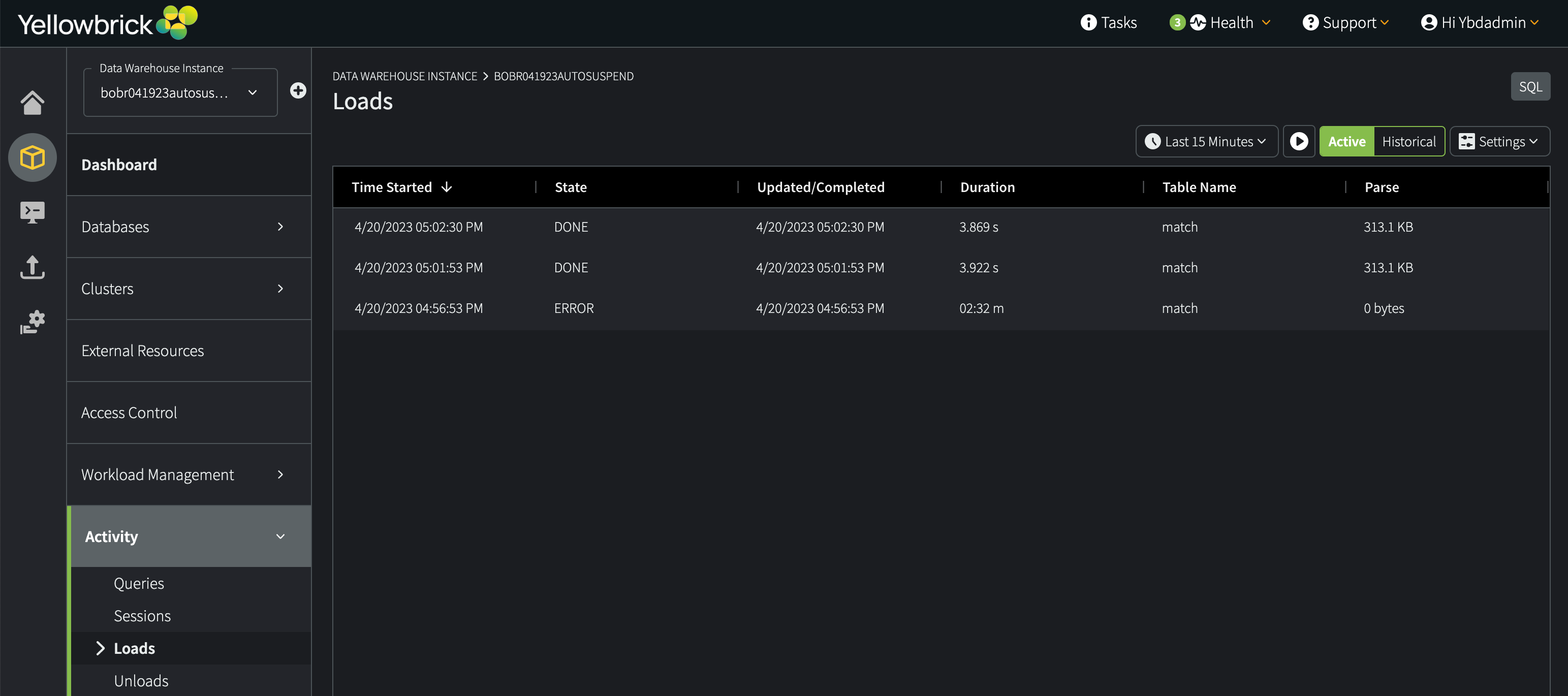
You can adjust the display in various ways, to see current versus logged activity data and to adjust the set of columns that are shown.
Sample Data
The Yellowbrick Manager Sample Catalog consists of several data sets (sample source files, DDL, and queries) that are maintained in and accessible from the YmSamples repository in GitHub. The DDL scripts in that repository reference AWS S3 files in a public bucket that you can load, using the Yellowbrick Manager. You can use either the Load Assistant or SQL commands in the Query Editor.
Click the Sample Data button on the home page (or in the Query Editor) to get started:
The catalog provides easy access to scripts for building and loading several data sets that you can import and use during your testing:
gdelt: The GDELT Project is the largest, most comprehensive, and highest resolution open database of human society ever created. Just the 2015 data alone records nearly three quarters of a trillion emotional snapshots and more than 1.5 billion location references, while its total archives span more than 215 years, making it one of the largest open-access spatio-temporal data sets in existence and pushing the boundaries of "big data" study of global human society.NOAA GHCN-D: Weather observations for over 200 years collected from a large number of land-based weather stations. The source files are provided by the Registry of Open Data on AWS (RODA).nyc-taxi: Yellow and green taxi trip records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts.premdb: A tiny database that contains actual English Premier League soccer results for about 20 seasons, as well as a few details about each team in the league. You can run a script that creates and loads five small tables in about 5 seconds. These tables are used extensively in the main Yellowbrick documentation to provide simple, reproducible examples of SQL commands and functions.tpcds_sf1000: A 1TB version of the TPC-DS data set, which is frequently used by database companies for competitive benchmarking. This data set is pre-loaded into theyellowbrick_trialdatabase. Scripts are available for re-creating and loading these tables.NetFlow: a data set generated by a service that sits on network routers and collects information on IP traffic as it enters or exits an interface. This information includes source and destination addresses, ports, protocols, and the amount of data transmitted. By analyzing NetFlow data, a network administrator can summarize network activity, find sources of network congestion, and identify potential security threats.
For example, select premdb, then Setup/Load 1 on the right side of the screen:
Note: The YmSamples site and the referenced S3 bucket are both public. You do not need an AWS S3 account to access the source S3 data that will be loaded into the sample tables.
Parent topic:Provisioning the Data Warehouse