Appearance
Overview
This section introduces concepts, terms, and behavior that you need to be familiar with before attempting to back up and restore Yellowbrick databases.
Use Cases
The backup and restore feature primarily supports disaster recovery (DR) scenarios: cases where a Yellowbrick system is irreparably damaged or lost, or a specific database on a system is compromised. You can resolve these problems by restoring databases from cold storage to the same cluster or a dedicated DR system. To keep a DR system in sync with minimal overhead, you can use incremental restore operations, which apply changes to databases after they have been fully restored. "Cold storage" may be cloud-based object storage, local file systems, or mounted file systems that are accessible to the client.
You can back up and restore a database to the same data warehouse instance where the original database was created (or to another instance on the same VPC):
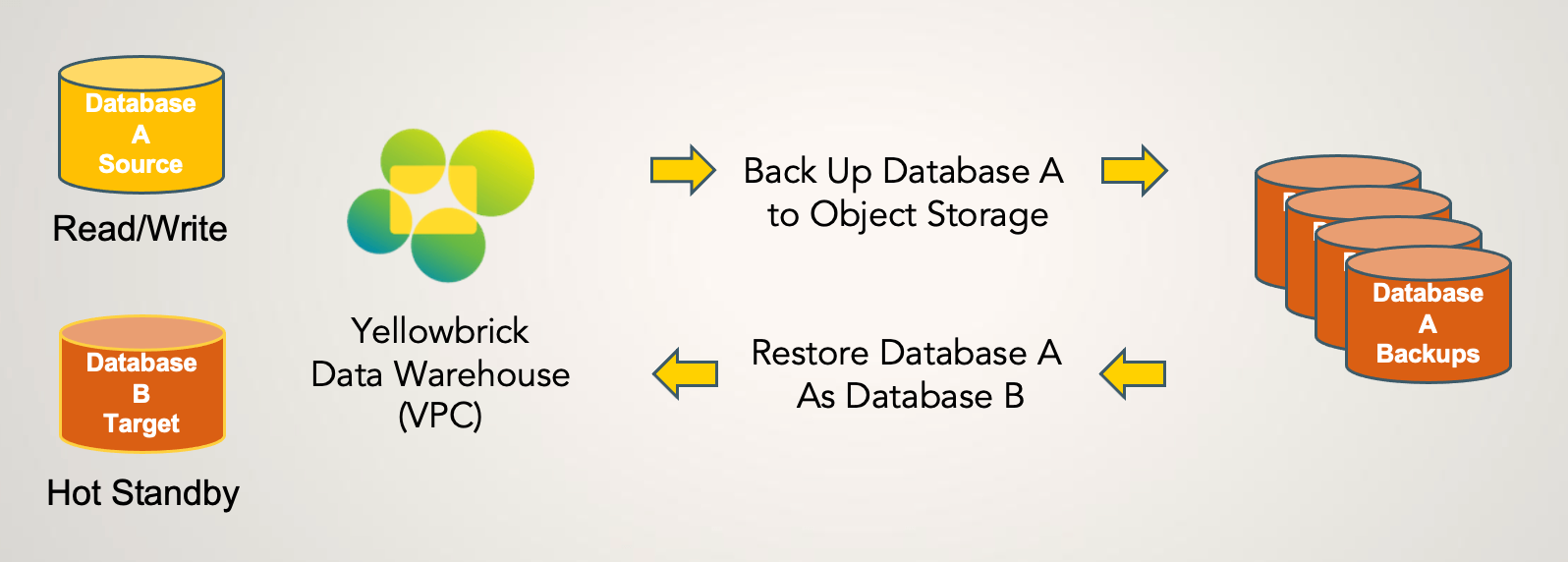
Alternatively, you can restore a database to a completely separate Yellowbrick instance on a separate VPC. In this example, the backup is taken on YB1, then restored to a new database on YB2.
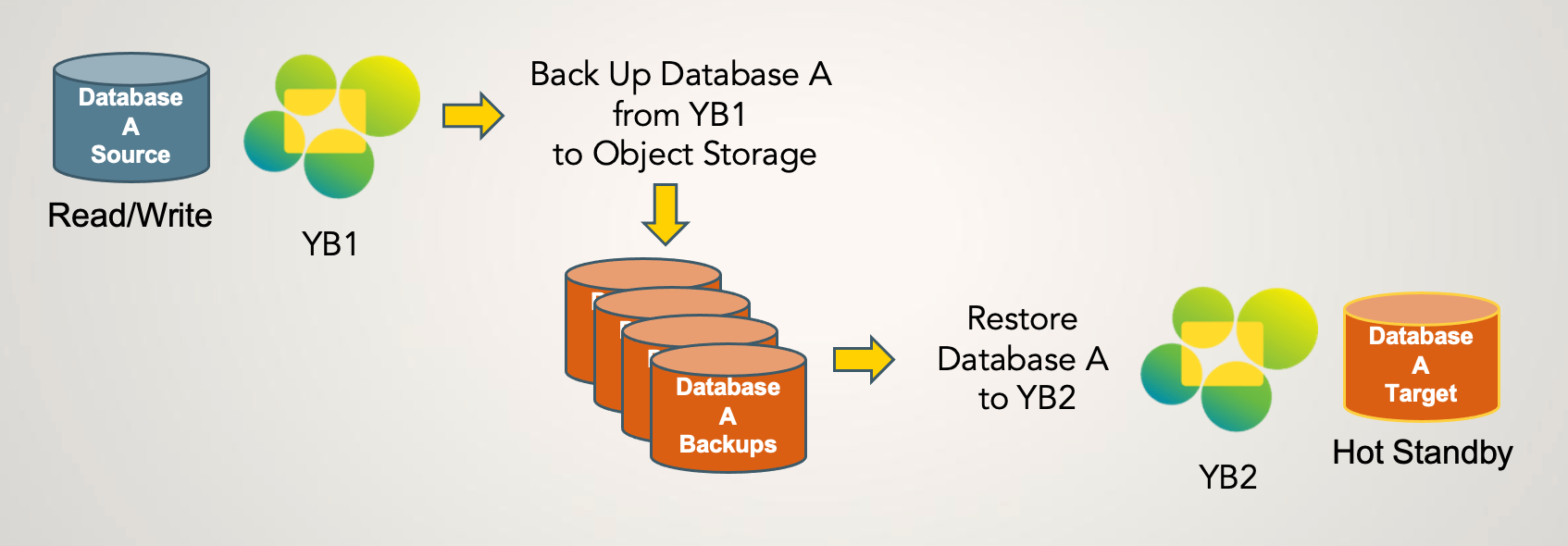
To facilitate database access on different systems, options are available to restore with or without shared security objects and attributes: users, roles, role memberships, and grants. You can also take backups that exclude specific schemas and their objects. See Scope of Backup Operations.
Another use case is the ability to make a copy of a database. You may want to copy a database under a different name, then use the new database as a separate development environment: for example, to test a specific workload or diagnose a problem without disrupting the source database.
Online Backups, Hot-Standby Restores
Yellowbrick supports online backups. Backup operations do not interfere with user queries or other database activities. Note that changes being introduced by running transactions that have not yet committed are not captured in a concurrently running backup. As soon as a transaction that changes the database commits, a subsequently started backup picks up those changes.
When you do an initial full restore of a database, the restored database is placed in "hot-standby" mode, allowing read queries and subsequent incremental restores but blocking other write operations. See HOT_STANDBY and READONLY Modes.
Backup Types
Yellowbrick supports backups at three different levels:
- Full: backs up the entire database from scratch.
- Cumulative: backs up all changes to the database since the last full or cumulative backup.
- Incremental: backs up all changes to the database since the last full, cumulative, or incremental backup.
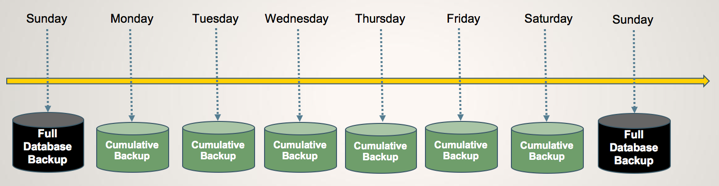
Important: Yellowbrick recommends two specific strategies for scheduling a sequence of backups:
- Full, followed by a series of cumulatives (no incrementals), and so on. For example:
- Full, followed by a series of incrementals, then a cumulative, then another series of incrementals, and so on. For example:
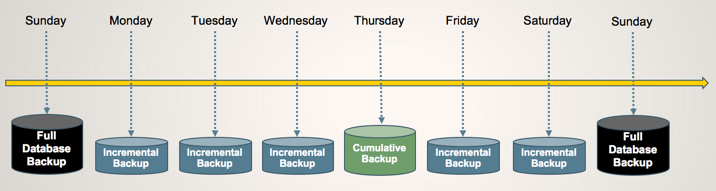
Note: See Backup Strategies for important details about restoring databases when incremental and cumulative backups are mixed.
The timing of backups in both cases depends on the size of the databases in question and how long it takes to do larger cumulative or full backups. For example, in the second case a cumulative backup might occur every weekend rather than during the week. In both cases shown here, a full backup might be done only once a month or once every three months.
If you are using incremental backups, you can delete the physical backup files periodically, sometime after the cumulative backup is taken. You can use ybbackupctl commands to delete backups. In the same way, you can delete cumulative backups sometime after a full backup is taken.
Although other combinations of backups may work, as a best practice Yellowbrick recommends these two strategies.
Scope of Backup Operations
A single ybbackup command backs up a single named database. Within a full backup, you can exclude one or more schemas and all of the objects they contain. You cannot exclude tables or other objects independently.
A database backup includes the following items (or changes to the following items):
- All schemas (except where one or more schemas are explicitly excluded from full backups)
- Tables and views (temporary tables are not backed up)
- Data in tables
- Stored procedures
- Sequences
- System catalog
- Users and roles (may be excluded when the database is restored)
- Ownership and permissions on database objects, including granted privileges and role memberships (may be excluded when the database is restored)
Note: Other shared (system-level) artifacts are not backed up:
- WLM profiles
- External storage, location, and format objects)
- Table statistics (they are recalculated and re-created when a database is restored)
- Encryption keys for SQL access, as created with the
CREATE KEYcommand
All backup files are saved in a proprietary format, and the data is not encrypted. Users cannot access these files directly, and restore operations work only when the target is a Yellowbrick cluster. If you need to encrypt backup data at rest, implement encryption within your storage system.
Backup Chains
A backup chain defines a sequence of backups that are stored in the same backup location and belong to the same, single database. A backup location is a path to a target directory on a storage system. A chain of backups in a specific location is also known as a backup set or a backup bundle.
A full backup occurs by default the first time you back up a database under a new backup chain. When you take a new full backup of a given database in a given location, you break the existing backup chain and start a new one.
To reclaim space, it is recommended that you drop backup chains with a SQL command when they are no longer needed:
- If you are running daily full backups, drop the backup chain as soon as each full backup completes. (Alternatively, use the same backup chain name every day; when each full backup is taken, the existing chain will be overwritten.)
- If you are using incremental backups, drop the backup chain as soon as you are certain that no further backups will be required for that chain.
You can use the ybbackupctl tool to delete physical backups from the file system.
Backup Points or Snapshots
A backup point or snapshot represents a specific point in time for a database, with metadata that defines the last transaction that committed before the snapshot was created. This point in time serves as a reliable record of the database state at that time: which tables and views were present, how many rows they contained, and so on. When you back up a database with the ybbackup tool, a snapshot record is implicitly created in the system and is visible in the sys.backup_snapshot view.
Scope of Restore Operations
You can restore either a database (all objects) or a single table from a backup. You can also restore security-related objects: roles, users, and ACLs. See ybrestore Options.
For single-table restores, the restored version of the table may be written to the same system, database, and schema where it was created, a different schema, a different database, or a completely different system. See Running a Single-Table Restore.
WLM Resources for Backup and Restore Operations
Backup and restore operations are assigned by default to the large pool in the Default profile. In some cases, this pool provides adequate resources for intensive write operations. However, you can create your own pools and WLM rules to run these operations if the Default profile cannot manage them efficiently.
You may need to use resource pools that have more memory or a higher maximum concurrency; 16GB per worker is a recommended minimum amount of memory, regardless of the Yellowbrick platform where your application is running. If you do not set up your WLM profile and resource pools to allocate a 16GB minimum, backup and restore operations may run out of memory. This recommendation applies to regular backup and restore operations and database replication.
In This Section
Parent topic:Backup and Restore