Appearance
Databases and Data Storage
A new instance contains the default yellowbrick database, and you can create new databases in Yellowbrick Manager or via a standard SQL command. For example:
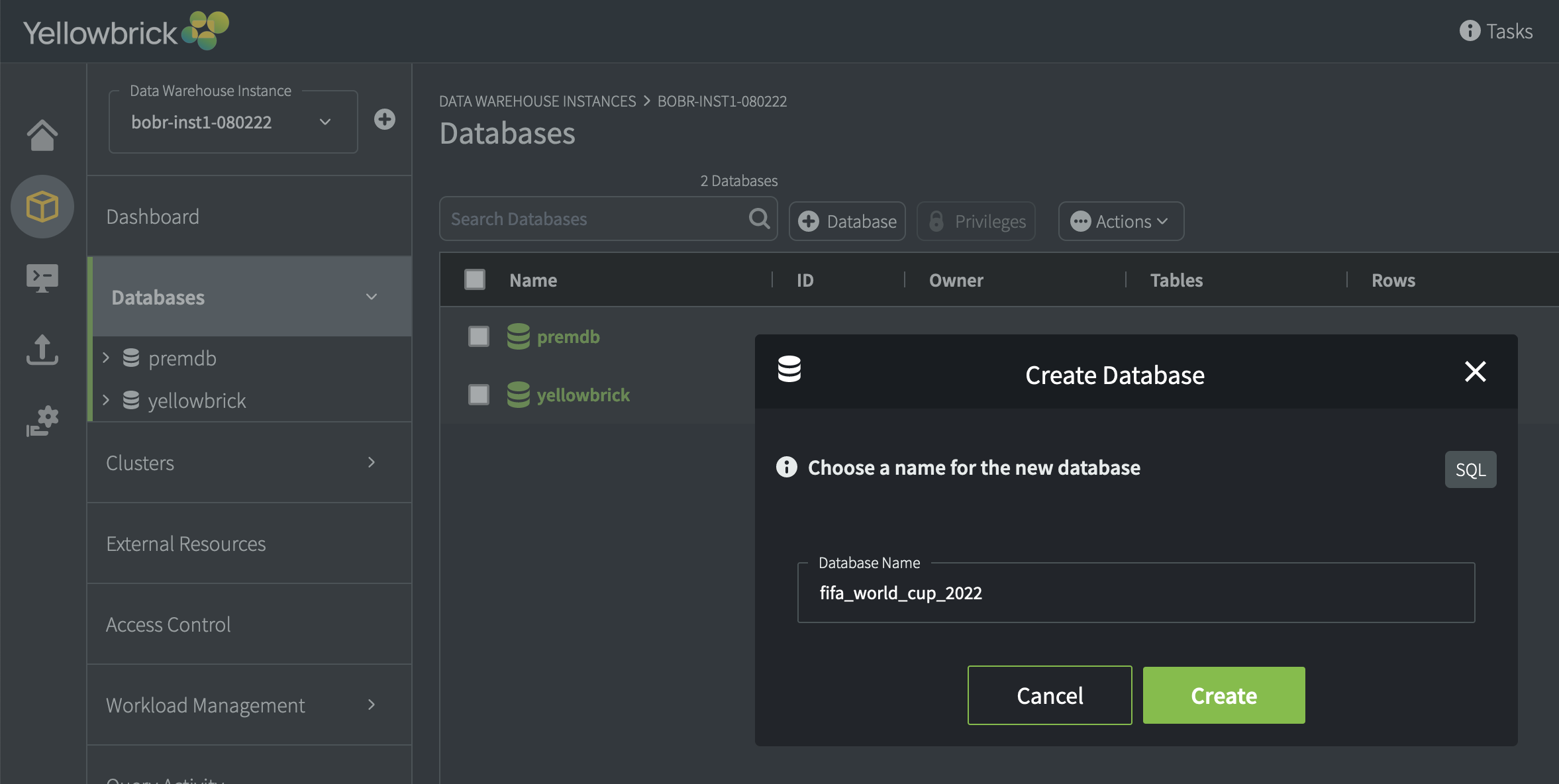
Note: Databases and the objects they contain belong to instances but not clusters. You can run queries and other operations against a database using any available running cluster in the current instance where you are connected. If the cluster you want to use is suspended, it will automatically resume when the first query is submitted against it (assuming that the auto-resume option was set for the cluster).
Database Objects
The Databases screen shows a list of the available databases and some information about them, including schemas, number of rows, and size. Select a database and schema from the list to see more details.
For example:
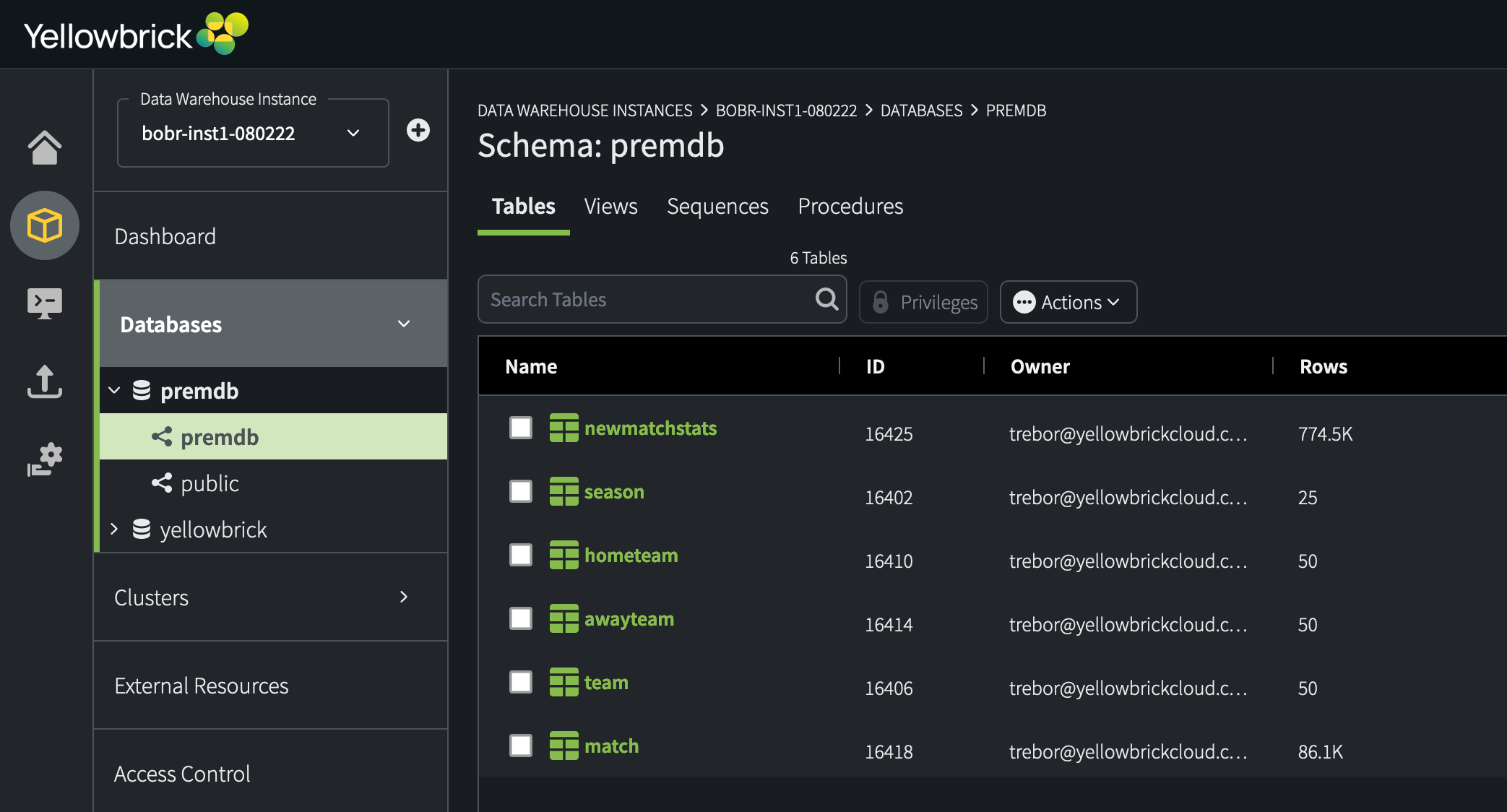
Select an object type from the horizontal menu bar to see more information about that type of object, such as Tables or Views.
Select an object from the list to drill down. For example:
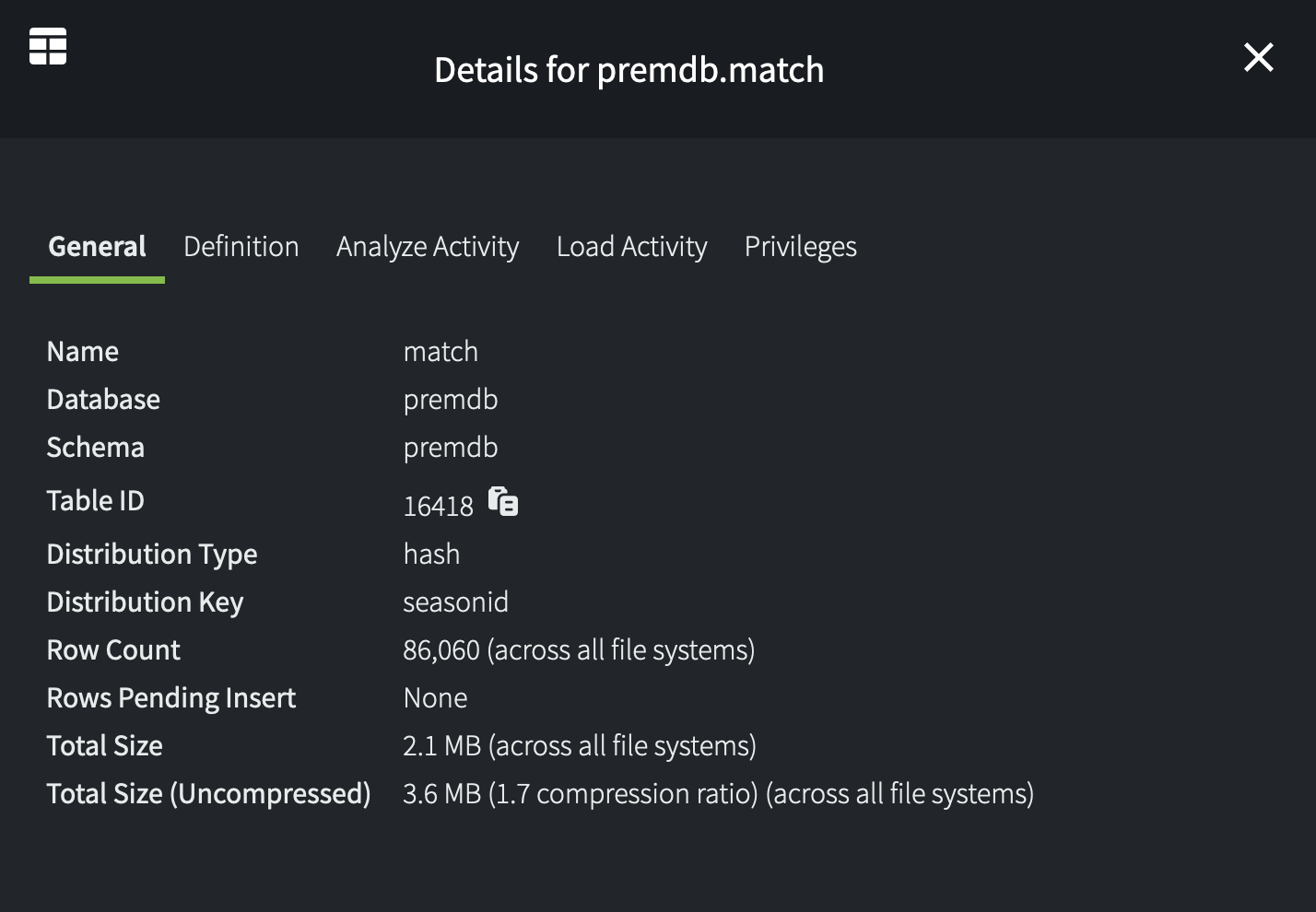
Data Storage
By default, object storage for the data that is loaded into your databases (shards that contain table rows) is created automatically when you create an instance. You do not need to create or modify "backend" database storage. Shards for all table data are directly persisted in object storage, bypassing the data cache that is provided by the local NVMe SSDs.
However, if you want to use your own object storage, you can do that by deselecting the Create initial external storage option when you create an instance. After that, use the CREATE EXTERNAL STORAGEandCREATE EXTERNAL LOCATION commands to configure "primary storage" for the instance.
In general, data storage capacity is unlimited. If necessary, you can apply disk quotas for individual databases, schemas, and tables.
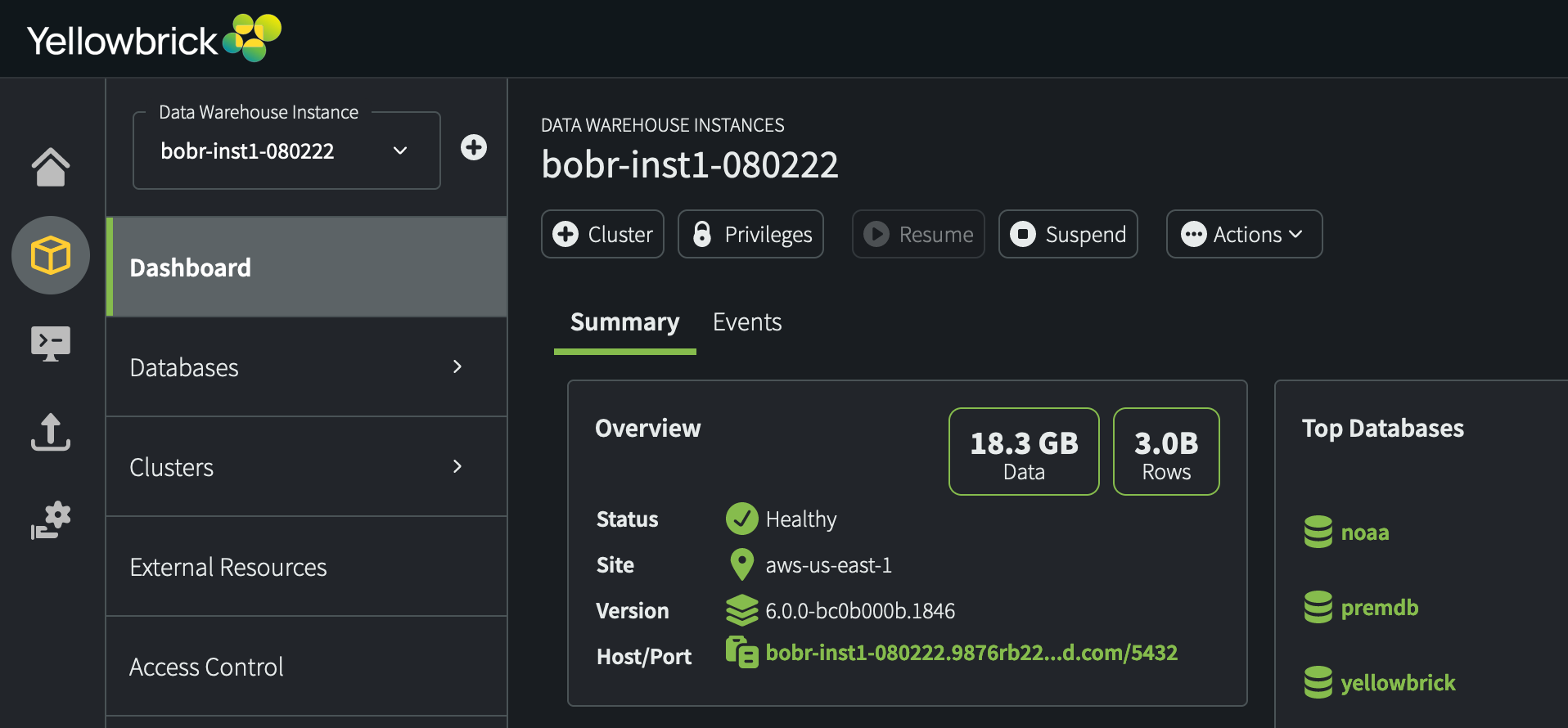
To see how much Yellowbrick data is currently stored in your databases, check the Overview section on the Dashboard for your instances.
For example:
Data Cache
When they are requested by read queries, blocks of data are cached in local NVMe SSDs. As the cache is "warmed" or "hydrated," queries over the same data or will see optimized performance. The data cache is managed at the cluster level; every cluster has its own cache that does not influence the behavior of queries executed against other clusters. The size of the cache for a cluster is visible as its Local Storage. You can also track the Cache Efficiency percentage per cluster.
The data cache consists of blocks of data (not whole columns or tables), and uses an LRU eviction policy to free space in the cache as new blocks are read during query execution. The cache is divided evenly into "hot" and "cold" segments. The first read of a block sends it to the cold cache; as blocks are requested again, they are moved to the hot cache. Blocks are evicted from the cold cache as the cache fills up, with the oldest blocks being evicted first.
In practice, a workload that consists of repeated queries over the same tables will benefit significantly from caching. For example, if the exact same query is run twice in succession on the same cluster, cache hits will account for all the blocks. Other typical examples of caching occur when parts of a query plan do not have to read from storage. If a range of rows for years between 2000 and 2010 is selected for one query, and a second query selects data for years 2000 to 2020, the second query will not have to re-read all of the blocks for that broader date range. Conversely, runaway queries or scans against very large fact tables may cause the cache to fill up with blocks from one table, to the detriment of subsequent queries against other tables.
When you create or alter a cluster, you can adjust the default ratio of cache and spill space (temporary space) as percentages of total disk space. By default, the ratio is 70% cache to 30% spill space.
Parent topic:Provisioning the Data Warehouse