Appearance
Databricks Integration Overview
Yellowbrick integrates seamlessly with Databricks through multiple approaches, supporting efficient analytics and machine learning workflows.
1. Yellowbrick as Gold Medallion Layer
Databricks excels at landing semi-structured and unstructured data and transforming and enhancing it into a consumable dimensional model for business analytics. Their Medallion architecture describes a data design pattern that uses:
- A Bronze layer for landing raw, unstructured data
- A Silver layer used for data transformation and augmentation
- A Gold layer for business level metrics, reporting, and dashboards
The problem many companies have is that Databricks becomes prohibitively expensive for the widespread distribution and responsive reporting businesses need. This stifles analytics in several ways:
- Fewer datasets are made available, limiting topics of inquiry.
- They are made available to fewer people, preventing democratization of analytics.
- The depth of the data or the complexity of the queries are limited, preventing root cause analysis.
To alleviate this, companies augment their medallion architecture by leveraging the performance and efficiency of Yellowbrick in the Gold layer.
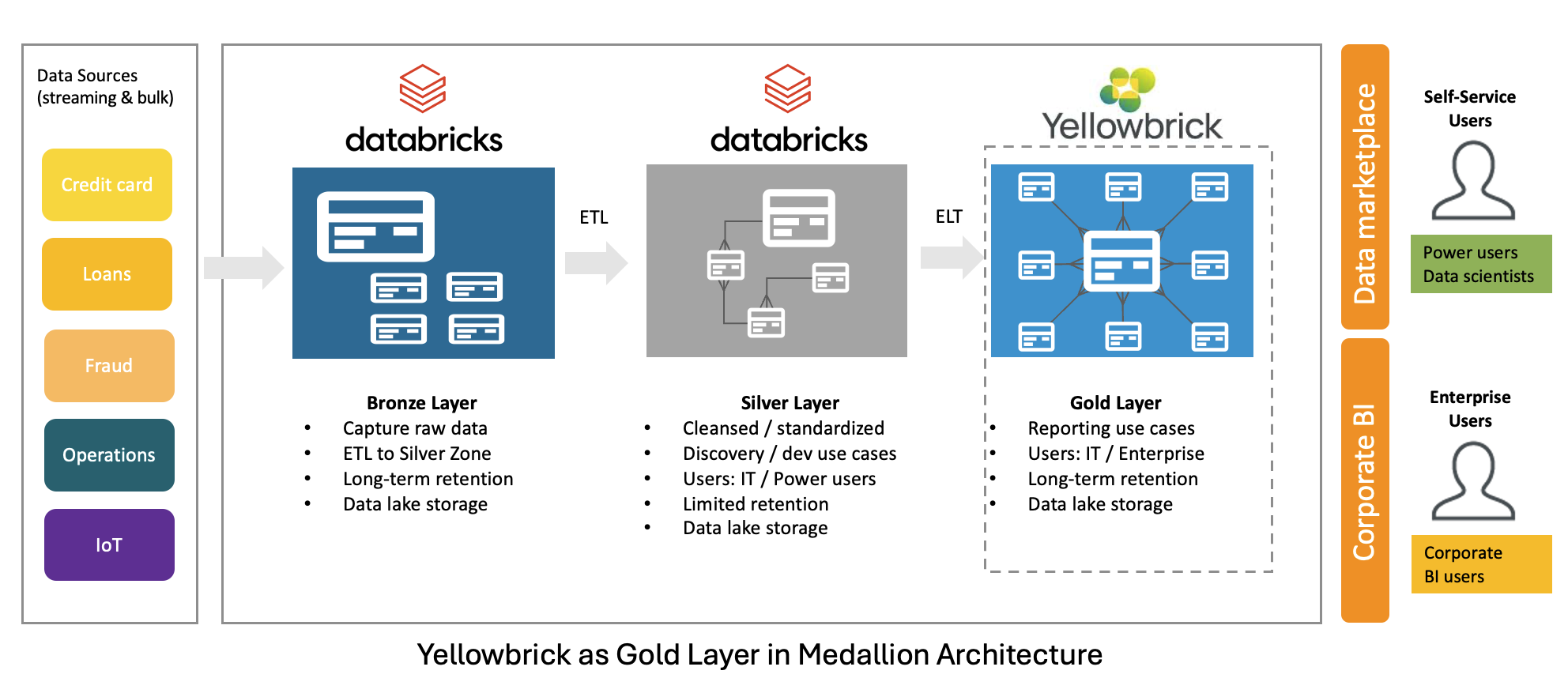
2. DB2YB Utility
To facilitate this architecture, Yellowbrick provides a ready-made notebook containing Python code published on GitHub that streamlines the creation and maintenance of the gold layer in Yellowbrick.
Features include:
- Extracting data from Databricks tables or Delta Lake sources
- Bulk-loading data into Yellowbrick for optimal performance
- Support for batch and incremental load patterns
- Support for maintaining lineage information within Databricks via shadow schemas
Refer to the documentation and usage guide here: db2yb Utility Guide
3. Unity Catalog Integration
As companies use Yellowbrick for the Gold Layer and it becomes their corporate "Version of the Truth," this integration sometimes happens in reverse. The data scientists know that the most cleansed and accurate version of the data exists in Yellowbrick. Therefore, they use Databricks Unity Catalog to map those Yellowbrick tables and seamlessly bring them back into their AI/ML pipelines. In some cases, the insights drawn from these models are fed back into Yellowbrick as brand new measures.
Databricks Unity Catalog allows companies to register Yellowbrick as an external PostgreSQL data source, enabling read-only queries of Yellowbrick data directly from Databricks notebooks and SQL warehouses.
Key highlights:
- Ideal for accessing cleansed and curated "Gold" data in Yellowbrick for advanced analytics and ML workloads
- Data can be accessed directly through Notebooks, Spark Jobs, or SQL Warehouses
- New measures can be fed back into the Yellowbrick Gold layer
See the detailed guide: Unity Catalog Integration Guide