Appearance
Replication Failover and Failback
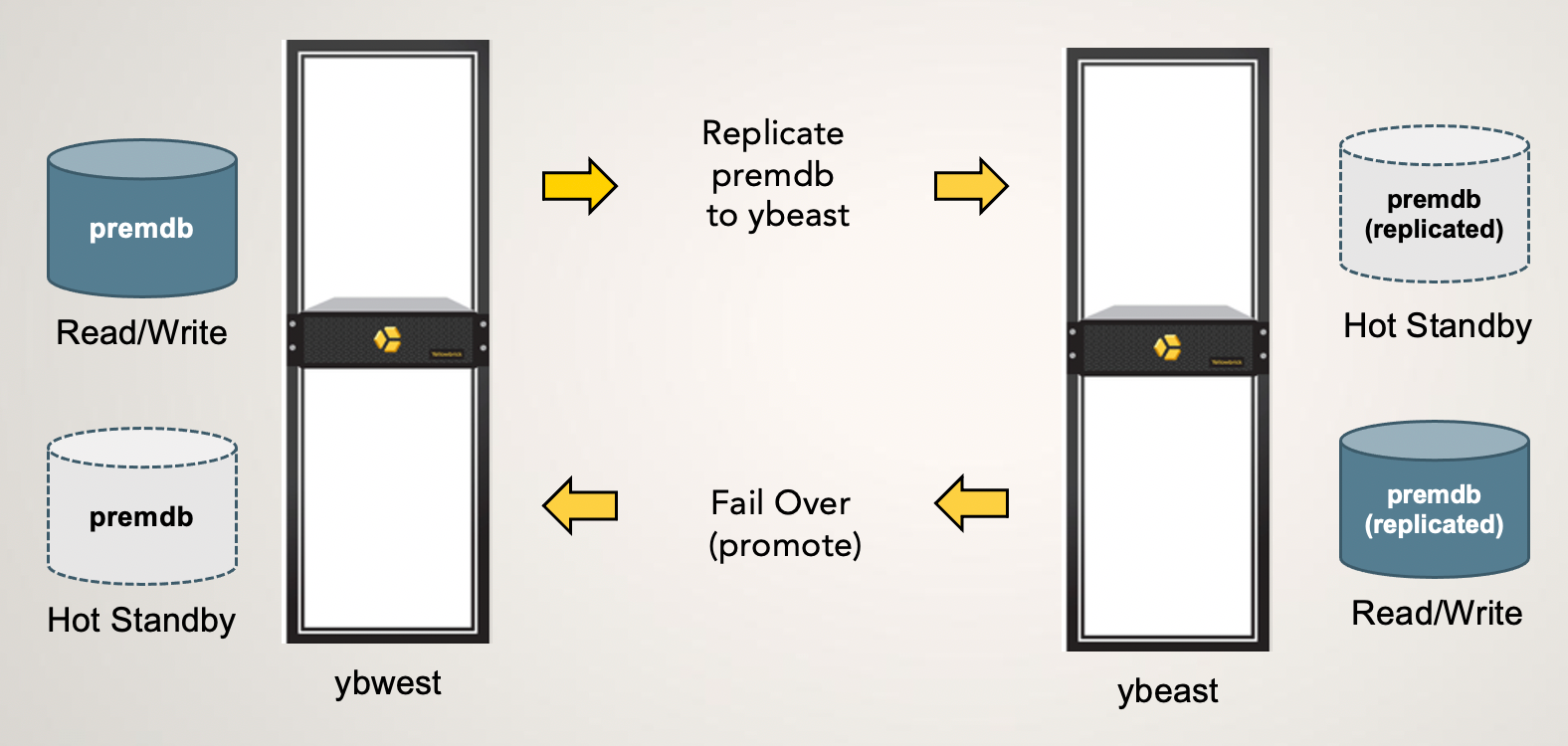
This section contains procedures for failing over and failing back (in the context of using database replication). The example in this section is based on the following configuration of clusters, databases, and replicas:
| Cluster | Remote Server | Source Database | Replica | Replica Database | Reverse Replica |
|---|---|---|---|---|---|
| ybwest (primary) | ybwest_svr | premdb | premdb_replica | premdb_replicated | N/A |
| ybeast (secondary) | ybeast_svr | premdb_replicated (after failover) | N/A | premdb (after failover) | reverse_premdb_replica |
Set Up Replication on the Primary System
Assume that replication has been started in the usual way, replicating data from the primary to the secondary cluster. The primary cluster is ybwest and the secondary is ybeast. The ybwest system has a database called premdb that replicates data to a database called premdb_replicated on ybeast.
The following commands were run on the primary cluster, ybwest:
yellowbrick=# create remote server ybwest with (host 'ybeast');
CREATE REMOTE SERVER
yellowbrick=# alter database premdb add replica premdb_replica to ybwest
with (alias premdb_replicated, frequency 60);
ADD REPLICA
yellowbrick=# alter database premdb alter replica premdb_replica start;
START REPLICAReplication is running, and incremental changes to the source premdb database are being streamed to the replica database, premdb_replicated, on the secondary cluster, ybeast.
Prepare for a Possible Failover Event on the Secondary System
To be ready in the event of a problem with the primary system, you need to create a reverse replica on the secondary system. When the time comes to fail over, you will use this replica to reverse the direction of replication. Follow these steps:
- Make sure SSL trust is fully configured in both directions between the two systems. See Configuring SSL Trust.
- Create a remote server on the secondary system. For example:
yellowbrick=# create remote server ybeast with(host 'ybwest');
CREATE REMOTE SERVER- Log into a database on
ybeastand create a reverse replica. For example:
yellowbrick=# alter database premdb_replicated
add replica reverse_premdb_replica to ybeast
with(alias premdb, reverse_replica premdb_replica, frequency 60);
ADD REPLICANote that this command refers to the following objects:
Database being altered:
premdb_replicated, which is the replica database that was created when replication was first set up (the target forpremdb).New replica being added:
reverse_premdb_replica(a new and unique replica name)Remote server created on the secondary system:
ybeastDatabase
ALIAS:premdb, which is the name of the original source databaseREVERSE_REPLICA:premdb_replica, which is the name of the original replica forpremdbNote: Allow some time for forward replication to start before trying to create a reverse replica. The best approach is to wait for one replication cycle to complete.
Fail Over: Promote the Secondary System
Assume that the ybwest cluster cannot function as the primary system for some reason, and that replication from ybwest to ybeast needs to be paused or has stopped running. You can now reverse the roles of the two systems and fail over to the secondary system, ybeast.
To fail over, run the following PROMOTE command, using the reverse replica you created in preparation for this failover event:
yellowbrick=# alter database premdb_replicated alter replica reverse_premdb_replica promote;
PROMOTE REPLICATo summarize, this command takes the premdb_replicated database out of HOT_STANDBY mode and allows you to start using this database for read and write operations. When the ybwest cluster comes back online, replication will proceed in the reverse direction so that the premdb database receives changes from premdb_replicated and can "catch up." For more details about what happens in the background when you run the PROMOTE command, see Fail Over With or Without Data Loss.
The PROMOTE command starts replication in the reverse direction; you do not have to run a START command.
Fail Over With or Without Data Loss
The PROMOTE command operates in two modes:
ALTER DATABASE name ALTER REPLICA name PROMOTE
or
ALTER DATABASE name ALTER REPLICA name PROMOTE WITH DATA LOSSIf you use the PROMOTE option (without data loss, as described in the previous section), the command tries to force replication from the primary to the secondary and rolls back the source database to a known good rollback point for both databases. If the database on the primary system cannot be reached when the PROMOTE command is run, the system returns an error. In this case, you can run the command again, using the PROMOTE WITH DATA LOSS option.
When you use the PROMOTE WITH DATA LOSS option, the command does not try to force replication from the primary to the secondary. Whatever differences in data existed between the two databases at the time of running the command will exist when replication is reversed. Data written to the primary may be lost because it was not replicated.
The following diagrams illustrate what happens in the background when you run the PROMOTE command. The first diagram shows the first case (without data loss):

The second diagram shows what happens when PROMOTE WITH DATA LOSS is used.

The main difference is that replication is not forced when the secondary system is promoted, meaning that data that was waiting to be replicated may be lost. The primary system is rolled back to the last backup point that the two systems shared.
Consider the following example, which describes a failover scenario where data committed to the primary system has not yet been replicated, and the primary system is not responsive (System A = primary, System B = secondary):
- System A replicates successfully to B for several cycles.
- Tables
t1throught100are in sync on both systems. Tablest1throught99are fully loaded, butt100is empty on both systems. - During loading of table
t100, System A becomes unresponsive and requires maintenance. 50 million rows were committed tot100before the failure. - A failover to System B is initiated.
PROMOTE...WITH DATA LOSSis run; there can be no attempt to replicate the last set of changes from A to B; 50 million rows int100are effectively lost. - A full load of 100 million rows into
t100is started and completed on B. - System A is repaired and brought back online.
- Replication starts in the reverse direction from B to A. All 100 million rows in
t100must be streamed to B from A.
Consider the same scenario without data loss: in this case System A is responsive after the failure occurs, so a replication cycle is feasible as part of the failover operation:
- Replication is forced, and both systems have 50 million rows in
t100when B is promoted. - The remaining 50 million rows are loaded into
t100on System B. - System A is repaired and brought back online.
- Replication starts in the reverse direction from B to A. 50 million rows in
t100are replicated.
When You Are Ready, Fail Back
When you are ready, you can revert to the original replication setup, from ybwest to ybeast. All you need to do is run a PROMOTE command that fails back to the primary system.
On the primary system, ybwest, run the following command from a database other than premdb:
yellowbrick=# alter database premdb alter replica premdb_replica promote;
PROMOTE REPLICAREADONLY Mode for Source Databases On Restart
A source database for replication typically accepts all read and write transactions. However, if the system goes down or has to be restarted, source databases are temporarily placed in READONLY mode. After the restart, there will be a short delay before the source database accepts all transactions and replication cycles can resume. The same behavior occurs after an upgrade.
This behavior protects the two systems in the replication topology while a number of validation checks are performed. The system verifies that the database has a replica in RUNNING state and that the target system can receive replication traffic. When these conditions are met, the source database is taken out of READONLY mode and replication can resume.
You can query the sys.database view or use the ybsql \l command to check the current state of your databases. The sys.database view has a readonly_reason column that indicates why the database was placed in READONLY mode.
Parent topic:Managing Replication