Appearance
Setting up and Running a Spark Job
This section describes the setup required to run a Spark job that loads a Yellowbrick table.
About Spark Jobs
Spark jobs can be submitted in various ways (standalone, cluster mode, using YARN as a resource manager, and so on). For details, see the Spark documentation.
In general, a Spark job consists of:
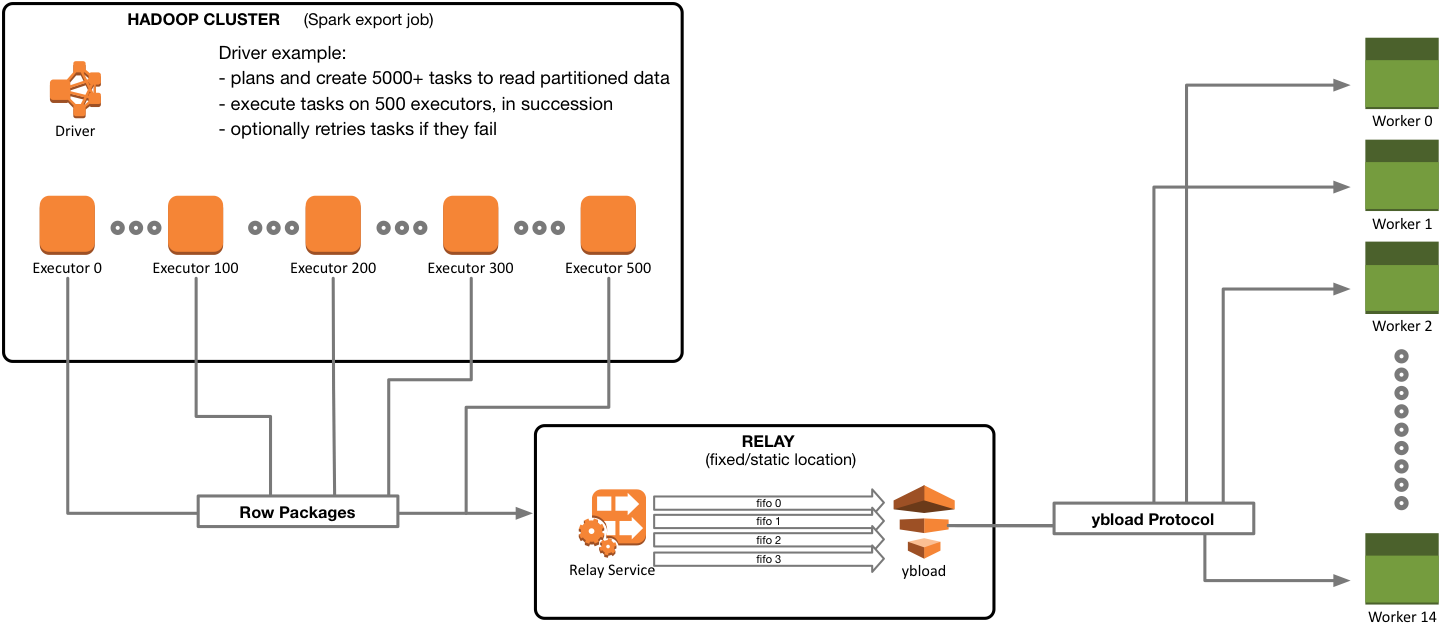
N + 1 compute (N executors, 1 driver)The driver executes first:
- Driver can run inline with the CLI submission or on-grid
- Driver plans and executes tasks on executors
Executors run tasks, and each task is given a slice of the data. Executors only need 2 cores and 1GB of memory.
A Spark job for Yellowbrick submits an application that uses ybrelay to stream high volumes of data into the table in parallel. Any file format that the Spark application can read is supported; ybrelay runs as a service that accepts row packages from Spark, then sends the data in parallel streams to ybload for fast bulk loading, as shown in the following diagram.
Summary of the spark-submit Command
A Spark job runs with a set of native Spark options and Spark application options. The source directory for the data must be specified, along with its format. Connectivity to both the Yellowbrick system and the ybrelay client must also be specified. Many other optional settings may be provided, including column information for the table, pre- or post-processing SQL to run, and options that are passed to ybload.
Note that ybrelay runs with its own set of options; these are not set in the Spark job. See ybrelay Options.
The spark-submit or spark2-submit command consists of multiple sets of parameters:
- Native Spark options, which vary by use case:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
...The --class option must be set to:
--class io.yellowbrick.spark.cli.SparkExport \- The Yellowbrick Spark application jar:
/opt/ybtools/*version*/integrations/spark/relay-integration-spark*shaded*.jar \- Yellowbrick Spark application options that define the source directory and format of the data, connectivity to the Yellowbrick database, connectivity to the
ybrelayservice, and other optional settings:
--export-directory hdfs:///user/warehouse/hive/${schema}.${table} \
--format parquet \
--yb-host $YT_HOST \
--yb-port $YT_PORT \
--yb-user $YT_DEFAULT_USER \
--yb-password $YT_DEFAULT_PASSWORD \
--yb-database $YT_DEFAULT_DATABASE \
--yb-table "${schema}.${table}" \
--yb-relay-host $YT_RELAY_HOST \
--yb-relay-port 21212 \
--log-level DEBUG \
...ybloadoptions that can be passed through thespark-submitcommand if needed:
--load-option "--max-bad-rows 0" \
--load-option "--on-missing-field SUPPLYNULL" \
--load-option "--on-extra-field REMOVE”
...In This Section
Parent topic:Loading Tables with Spark